
This topic explains the syntax tree pruning types performed by the Syntax Parsing Engine.
The following topics are prerequisites to understanding this topic:
This topic contains the following sections:
It may be necessary for organizational purposes, error handling behavior, ambiguity resolution, or other reasons for the grammar writer to include extra non-terminal symbols in the grammar definition that shouldn’t be included as nodes in the final syntax tree. There are two types of pruning which can be used to exclude these symbols from the syntax tree:
To change the types of syntax tree pruning use the Grammar.SyntaxTreePruningMode property and set it to a value of type SyntaxTreePruningMode. By default, both pruning modes are enabled.
In many cases, it makes sense to include certain “helper” non-terminal symbols in the grammar definition which can decrease grammar complexity or prevent common patterns from being repeated in an EBNF file. Most of the time, these non-terminals symbols should not have associated nodes in the syntax tree, so they can be excluded by naming them with an underscore as the first character, as in the following example:
FieldDeclaration =
_typeMemberPrefix, Semicolon;
MethodDeclaration =
_typeMemberPrefix, ParameterList, MethodBody;
PropertyDeclaration =
_typeMemberPrefix, PropertyBody;
_typeMemberPrefix =
[Attributes], [Modifiers], Type, Identifier;
When the syntax tree is pruned based on name, all non-terminal symbols which start with an underscore will never appear as nodes in the tree and their child nodes will be promoted up to be children of the next included parent node in the tree.
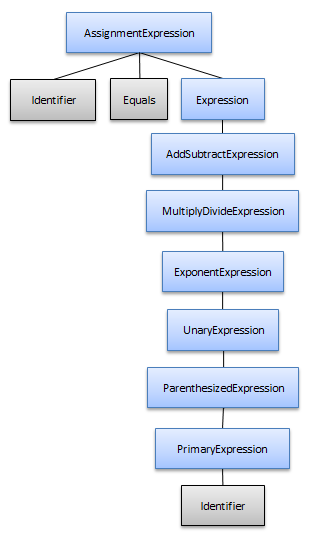
A common way of preventing global ambiguities when defining operator rules is to arrange the rules in such a way so that lower precedence operations “own” higher precedence operations, thereby allowing the higher precedence operations to be grouped together with their operands. A side effect of this arrangement is that the more common simple expressions, such as an identifier referenced by itself, could lead to a very dense syntax tree where the identifier node is owned by nodes representing each lower precedence level.
For example a simple assignment expression like “x = y” may lead to a syntax tree structure like this:
However, with the “based on children” pruning, the syntax tree will look like this instead:
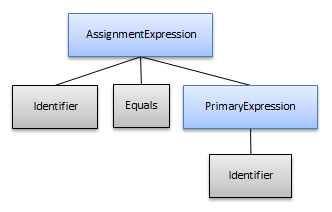
This pruning mode removes any non-terminal symbol node which owns a single non-terminal symbol node. The child non-terminal symbol node is then promoted to be a child of the next included ancestor node.
The following topics provide additional information related to this topic.